陰莖敏感反應的神經網路技術學習之路
南爵總研於陰莖敏感反應的神經網路技術學習之路
一、訓練過程各階段判讀由人工轉系統
南爵針對陰莖敏感反應的判讀於2012年成熟後,為了能夠有效降低人力負擔,並方便整合醫療資訊、營養資訊、行為資訊、運動資訊、情緒資訊、陰莖反應資訊,將整套訓練方式提升至以系統取代人工,達到訓練可透過系統自動判別有效取代訓練上的沉重人力。

二、採用多層次堆疊的邏輯推理方法
在資料整合完畢後,初期我們決定採用多層次堆疊的邏輯推理方法協助判讀。初期設計先透過真實事件的發生,也就是真實的針對陰莖的表現狀態收集數據單一單元(先以單一單元解釋),然後在分類數據的過程中同步進行篩檢判讀。
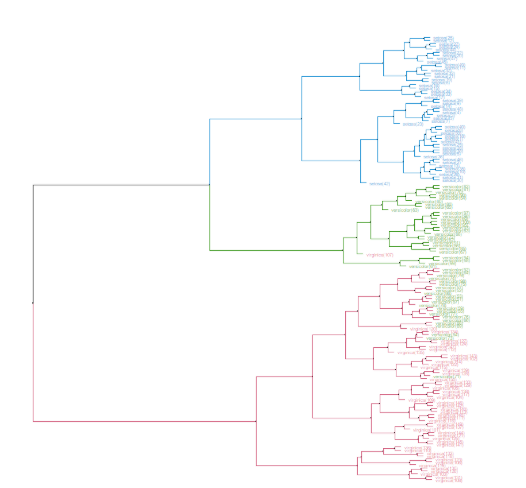
比如反應強弱變化的二維分析,再針對反應的細微變化比如情緒,充血變化,以及敏感異動等等,產生堆疊式的二維分析,形成2的2次方堆疊與2的4次方堆疊,隨著變因越多堆疊的次方樹狀圖就越大。如果再加上特異性與個體化,就會形成判讀上的越來越精細,同時我們也更能夠分析出真正的重要因子。
而這樣的做法也揭露出,越早期的判讀顯顯得越粗糙。這也是代表一件事,我們往往想法與事實相差甚遠。比如早期以為自己陰莖敏感引起早洩,但是經過精細的數據分類判讀後發現原因竟然不是敏感,甚至發現自己陰莖其實是低敏感外,同時也發現是其他原因引起早洩。
雖然實質上可根據分類樹狀圖有效的做反應變化依循,找到數據單一單元與身體產生敏感異動及影響的原因,但是在多次方堆疊下,變因的影響過大,即使能有效的透過逆向檢測解決問題,但是還是會礙於設定因素與人為判讀上的差異,造成機器的判讀上產生阻礙。
三、陰莖的敏感反應是雙軌的影響機制
如果分析者本身對於人體的生理機制與功能沒有深度的理解,那麼即便數據檢測出來找到真實原因,也無法有效的設計學習策略。畢竟陰莖的敏感反應是雙軌的影響機制,一方面是身體反應的數據叢,另一方面是心理反應的數據叢,雙向交互所產生的結果。

四、解決方針系統化的困難
在針對陰莖的身體反應與心理反應對應上的交錯性,對應到人體大腦是神經元與神經元之間高達120 m/s速率的交流。 電腦系統必須花上數以千計的模擬測試,才能找出與實際現象相符的模擬情境,大量的運算在效率上遠遠低於人工判讀,過程中過高的數據維度分析也必須透過人為輔助降低維度,以降低模擬次數、提高效率。
即便在真實的訓練操作上我們已經能有效掌握正確的方法,但是對於形成數據資料庫到分類後系統能產生自動判讀的動作,我們還是沒辦法有效的成功自動化,所以我們也一直只能針對個人的學習上做出指導,無法走到一對百,一對千的群眾教育。
五、解決方針的擴展
即便我們已能做到對敏感反應問題能設計有效解決方針,但是無法自動化產出解決方案,實質針對每個學員的訓練,需投入的人力成本過高。所以當年我們也只能痛定思痛,持續擴充各種不同敏感反應問題的有效解決方針。 因此,南爵開始針對需要的反應族群進行新進學員的篩選,針對所需之陰莖數據資料做出收集,這也是為什麼過去我們在問卷上篩選學生之後,還會依據反應的特性做出分類。因為我們必須確切的確認每個原因與結構形成,才能有效的建立數據模型,所以我們才開始針對男性的病態狀況的陰莖數據做出研究。
六、未來方向的抉擇
過去我們從正常生理狀態的陰莖數據與學習產生了完美的數據學習結構與路徑,本來以為完全的線上化已經是早晚的事。但是當面對強化變因的判讀(如:男性退化,慢性病),以及各類的陰莖敏感反應受到破壞(如:手術、用藥),大腦的錯誤行為判讀(如:非正常方式的性交,對陰莖拍打,錯誤手淫,奇特方式射精等等),這些多元性的干擾,大大影響了我們原有的計畫,以及原先的自動學習路徑,因為這些多元性的干擾(有些甚至並非自然生成,而是所謂人為因素產生新的變異序列),如果要用正常的陰莖數據資料庫,根本無法有效判讀。
所以必須要重新建立數據庫。 也因為產生的變因並非是過去我們研究正常陰莖的變因序列,所以當時團隊面臨了方向上的抉擇: 到底要進行進一步的再繼續收集這些數據、擴充不同類型的解決方針,讓我們研究更完整? 還是直接進行商業化的營業? 真的是讓團隊進行了相當嚴重的討論。
七、自動化的再次嘗試
所以到2014年後在我們團隊意見分歧,成員各自離去後,我們決定暫停原有的招生計畫,開始針對這些人為變因數據開始收集,開始投入新的自動學習模型,針對許多不同的狀況設計模型。
我們就將這些會影響陰莖敏感變化的數據,重新建立並且優化為可以進行輸入比對。但是令人驚嘆的事情就這樣發生,人體針對身體的變因,以及環境適應的變化,會因為人格特性與思考,產生所謂反應上的不同表現。而亞健康狀態的身體模糊期,竟然也會讓身體的變因序列錯亂,身體會自行尋找適合當下環境的方式進行學習、形成新的慣性,這真的讓我們認為可以線上化作判讀的期望產生了致命的重傷害,所以變成我們也必須要再增加多元的判讀項目。
回到機器學習技術上,能夠做的是在解決現實中複雜的資料切割分類取代人類的判讀動作,但是對問題線性關係的資料只能用一條直線表示(比如陰莖敏感與疲勞指數變化成正比,或者陰莖充血速度與敏感強度成正比);但是如果遇到非線性關係的資料根本無法用線性方程表示(比如:情緒的變化量化指標與複合干擾因素) 而陰莖的變因干擾,就正是多個指數增長的複合干擾,不停地產生多面向的幾何成長以及幾何衰退,而回歸到個體後,更會有所謂的函數特性與時期不同的函數變化(如:情緒的高檔期、疲勞的低檔期等等)會需要不同的設計,這也是為什麼學員的訓練上每人都不盡相同,因此所需要的判讀方式與設計更是有特異性。
學員常常判讀錯誤,敏感與硬度正相關,但是在單獨判讀的時候會因為訓練時期的不同產生混雜。比如,成長期就屬於非線性不可單一判讀,而硬度穩定後就可以單一的判讀表達,相同的器官卻有著完全不同的行為模式與計算方法,更別說還要加上情緒反應與疲勞問題等等。另外,單一刺激源硬度,單一刺激源敏感,進入線性刺激可判讀,但是混和型的低敏感高硬度,高敏感低硬度,就會產生非線性資料,切割後又是完全不同的獨立表現,甚至是產生新的指標來源。
所以我們原先的神經網路單層線性模型,無法解決線性不可分問題,因此也讓我們的機器動態判讀的計畫產生較大的問題。
八、模型的建置
在2016年後我們參考用了反向傳播演算法來設計我們的陰莖敏感的神經網路。這邊簡易教學一下類神經網路的基本原理,先讓資料訊號通過網路,輸出結果後、計算其與真實情況的誤差;再將誤差訊號反向傳播回去、對每一個神經元都往正確的方向調整一下權重;如此來回個數千萬遍後,機器就學會如何辨識一種陰莖的敏感反應。在多次的資料倒流後,就可以針對多種的陰莖敏感反應做判斷。
反向傳播時,正常的資料處理會設定更正錯誤的方法──「代價函數」(Cost Function)。代價函數是預測陰莖敏感結果和陰莖敏感的真實結果之間的差距。代價函數的優化 (Optimization) 是機器學習的重要研究目標,也就是:如何找到優化的最佳解(機器判讀誤差的最小值)?如何用更快的方式逼近最佳解?
如何逼近最佳解有很多種不同的演算法,最典型的方法是採用隨機梯度下降法 (Stochastic Gradient Descent)。當線性關係資料的代價函數為凸函數,找到最佳解不是問題;然而問題在於非線性關係的資料:其代價函數為非凸函數,求解時容易陷入局部最佳解、而非全域最佳解,這個問題叫做梯度消失問題 (Vanishing Gradient)。
但糟糕的是,梯度消失問題會隨著神經網路層數的增加而更加嚴重,意即,隨著梯度逐層不斷消散、導致神經網路對其神經元權重調整的功用越來越小,所以只能轉而處理淺層結構(比如 2 層)的網路,從而限制了性能。(比如射精閥值神經元、情緒神經元、硬度神經元)
也因此我們的陰莖反應判別原本以為可以有效的突破神經網路學習的阻礙,多層次的學習存在著太深的技術阻礙,所以面對這樣的狀況,也只能透過人為篩選,將所有的陰莖敏感設定型態與定義,把深度學習的目的,切割成許多小區塊的淺層機器學習。
畢竟超過多層的神經網路學習,會造成多變因的錯誤,跟不可能的組合(比如陰莖敏感反應高昂興奮,但相關變數為重度疲勞,陰莖軟化,然後持久力提升。但是因為陰莖軟化跟持久力提升已經有很大的落差了,即便機器學習上是可行,但在人類真實行為上真的出現機率過低,所以我們機械學習的投資上線量化產生了阻礙)。
所以我們只能針對目前的狀態,以針對淺層的機械學習資料做設計(比如:分割為陰莖敏感與藥物影響、分割為陰莖敏感與營養影響、分割為陰莖敏感與高血壓、分割為陰莖敏感與營養影響、分割為陰莖敏感與持久力、分割為陰莖敏感與情緒刺激、分割為陰莖敏感與疾病影響、分割為陰莖敏感與情緒影響、分割為陰莖敏感與情緒影響、陰莖敏感與肥胖等等數以百計的小單元)。
再透過風險模型的設計,針對各項影響要素,根據個人的狀態,導入所需求的小單元,比如肥胖、手淫錯誤、情緒刺激等等建立小型的風險模型,再進一步的進行訓練方針上的改變去修正風險模型。等到訓練完成後,也就可以透過風險模型去預測是否會產生衰退,以及如何去預防。 但是問題點在於即便是建立風險模型,也要減少模型間干擾要素,比如疾病與情緒這兩個單元,容易有正相關,而這兩個正相關相依性過高就會產生所謂的數據偏差值提升,導致本來主角的陰莖敏感,被雙變因的數據相近給拉走,導致數據上會失準,所以我們就從小型的風險模型建立。未來我們就能夠在陰莖衰退以及產生影響與退化時,精準的找出原因,及時解決。算是對於我們多年投資上找到了新的出路。
這些年來我們也發現了有國外學者,成功解決了反向傳播的優化問題,我們也檢視過這樣的方法或許可行,我們的南爵訓練的陰莖數據資料早已分類好超過7萬筆,平均一個學員一年就能產生,600筆固定數據,可變形混合數據,更是可以達1800筆,雖然我們在深度學習的部分已經暫停了投資,改走向男性生理風險控管與陰莖強化結合,但是我們希望有朝一日可以有更高的技術單位可以一起與我們合作完成南爵數據在這門研究上的遺憾之珠。
九、後記:
深度神經網路可以自動學習特徵,而不必像以前那樣還要請專家以人工建造特徵,大大推進了智能自動化 (就好比陰莖受損了也在後續的特徵反應形成差異,那麼在設定權值與係數上的問題就可以自動解決) 。
而因為我們走的是以標註的資料,所以學習上希望的是依循產生的結果與對應方法,所以應用像是淺層學習的方法反而更適合我們。
雖然我們的進展最後只到淺層的學習,但是對於我們來說透過數據的學習知識上,也回歸到一個重點,就是是否掌握關鍵資料以進行分析。所以我們回頭針對最原始的資料開始進行分析、分類、趨向判定、以及解讀,並且朝向健康風險控管方向執行,也相信未來一定可以完成線上AI的判讀以協助訓練。
希望我們提出的數據與多年見解可以讓生物數據學習上更精進,也希望我們解釋錯誤上有問題可以給我們批評指教。如果有各單位在生物數據分析與學習上需要技術的合作都可以透過官方EMAIL與我司聯繫。
技術與參考
2006 年可以說是深度學習起飛的一年。經過了三十年的研究,Hinton在《Science》等期刊發文,指出「具備多層隱藏層的神經網路具有更為優異的特徵學習能力,且其在訓練上的複雜度可以通過逐層初始化來有效緩解」。
這篇驚世駭俗之作名為《Reducing the dimensionality of data with neural networks》。在這篇論文中, Hinton 提出深度信念網路、使用無監督預訓練方法優化網路權值的初始值,再進行權值微調 (Fine-Tune),讓多層神經網路能夠真正被實踐。
又由於神經網路的研究在過去被棄置已久,故 Hinton 教授又將深度神經網路重新換上「深度學習」(Deep Learning) 的名字捲土重來,Hinton也因此被稱為「深度學習之父」。
話說回來,目前已經沒什麼人在使用 RBM 或深度信念網路了;後來的研究發現,簡單的初始化和激發函數的調整,才是解決 Vanishing Gradient Problem 最好的方法。現今最為廣泛被使用的方法是「多層感知器 (MLP) + ReLU函數」。
南爵總研於陰莖敏感反應的神經網路技術學習之路
一、訓練過程各階段判讀由人工轉系統
南爵針對陰莖敏感反應的判讀於2012年成熟後,為了能夠有效降低人力負擔,並方便整合醫療資訊、營養資訊、行為資訊、運動資訊、情緒資訊、陰莖反應資訊,將整套訓練方式提升至以系統取代人工,達到訓練可透過系統自動判別有效取代訓練上的沉重人力。
二、採用多層次堆疊的邏輯推理方法
在資料整合完畢後,初期我們決定採用多層次堆疊的邏輯推理方法協助判讀。初期設計先透過真實事件的發生,也就是真實的針對陰莖的表現狀態收集數據單一單元(先以單一單元解釋),然後在分類數據的過程中同步進行篩檢判讀。
比如反應強弱變化的二維分析,再針對反應的細微變化比如情緒,充血變化,以及敏感異動等等,產生堆疊式的二維分析,形成2的2次方堆疊與2的4次方堆疊,隨著變因越多堆疊的次方樹狀圖就越大。如果再加上特異性與個體化,就會形成判讀上的越來越精細,同時我們也更能夠分析出真正的重要因子。
而這樣的做法也揭露出,越早期的判讀顯顯得越粗糙。這也是代表一件事,我們往往想法與事實相差甚遠。比如早期以為自己陰莖敏感引起早洩,但是經過精細的數據分類判讀後發現原因竟然不是敏感,甚至發現自己陰莖其實是低敏感外,同時也發現是其他原因引起早洩。
雖然實質上可根據分類樹狀圖有效的做反應變化依循,找到數據單一單元與身體產生敏感異動及影響的原因,但是在多次方堆疊下,變因的影響過大,即使能有效的透過逆向檢測解決問題,但是還是會礙於設定因素與人為判讀上的差異,造成機器的判讀上產生阻礙。
三、陰莖的敏感反應是雙軌的影響機制
如果分析者本身對於人體的生理機制與功能沒有深度的理解,那麼即便數據檢測出來找到真實原因,也無法有效的設計學習策略。畢竟陰莖的敏感反應是雙軌的影響機制,一方面是身體反應的數據叢,另一方面是心理反應的數據叢,雙向交互所產生的結果。
四、解決方針系統化的困難
在針對陰莖的身體反應與心理反應對應上的交錯性,對應到人體大腦是神經元與神經元之間高達120 m/s速率的交流。 電腦系統必須花上數以千計的模擬測試,才能找出與實際現象相符的模擬情境,大量的運算在效率上遠遠低於人工判讀,過程中過高的數據維度分析也必須透過人為輔助降低維度,以降低模擬次數、提高效率。
即便在真實的訓練操作上我們已經能有效掌握正確的方法,但是對於形成數據資料庫到分類後系統能產生自動判讀的動作,我們還是沒辦法有效的成功自動化,所以我們也一直只能針對個人的學習上做出指導,無法走到一對百,一對千的群眾教育。
五、解決方針的擴展
即便我們已能做到對敏感反應問題能設計有效解決方針,但是無法自動化產出解決方案,實質針對每個學員的訓練,需投入的人力成本過高。所以當年我們也只能痛定思痛,持續擴充各種不同敏感反應問題的有效解決方針。 因此,南爵開始針對需要的反應族群進行新進學員的篩選,針對所需之陰莖數據資料做出收集,這也是為什麼過去我們在問卷上篩選學生之後,還會依據反應的特性做出分類。因為我們必須確切的確認每個原因與結構形成,才能有效的建立數據模型,所以我們才開始針對男性的病態狀況的陰莖數據做出研究。
六、未來方向的抉擇
過去我們從正常生理狀態的陰莖數據與學習產生了完美的數據學習結構與路徑,本來以為完全的線上化已經是早晚的事。但是當面對強化變因的判讀(如:男性退化,慢性病),以及各類的陰莖敏感反應受到破壞(如:手術、用藥),大腦的錯誤行為判讀(如:非正常方式的性交,對陰莖拍打,錯誤手淫,奇特方式射精等等),這些多元性的干擾,大大影響了我們原有的計畫,以及原先的自動學習路徑,因為這些多元性的干擾(有些甚至並非自然生成,而是所謂人為因素產生新的變異序列),如果要用正常的陰莖數據資料庫,根本無法有效判讀。
所以必須要重新建立數據庫。 也因為產生的變因並非是過去我們研究正常陰莖的變因序列,所以當時團隊面臨了方向上的抉擇: 到底要進行進一步的再繼續收集這些數據、擴充不同類型的解決方針,讓我們研究更完整? 還是直接進行商業化的營業? 真的是讓團隊進行了相當嚴重的討論。
七、自動化的再次嘗試
所以到2014年後在我們團隊意見分歧,成員各自離去後,我們決定暫停原有的招生計畫,開始針對這些人為變因數據開始收集,開始投入新的自動學習模型,針對許多不同的狀況設計模型。
我們就將這些會影響陰莖敏感變化的數據,重新建立並且優化為可以進行輸入比對。但是令人驚嘆的事情就這樣發生,人體針對身體的變因,以及環境適應的變化,會因為人格特性與思考,產生所謂反應上的不同表現。而亞健康狀態的身體模糊期,竟然也會讓身體的變因序列錯亂,身體會自行尋找適合當下環境的方式進行學習、形成新的慣性,這真的讓我們認為可以線上化作判讀的期望產生了致命的重傷害,所以變成我們也必須要再增加多元的判讀項目。
回到機器學習技術上,能夠做的是在解決現實中複雜的資料切割分類取代人類的判讀動作,但是對問題線性關係的資料只能用一條直線表示(比如陰莖敏感與疲勞指數變化成正比,或者陰莖充血速度與敏感強度成正比);但是如果遇到非線性關係的資料根本無法用線性方程表示(比如:情緒的變化量化指標與複合干擾因素) 而陰莖的變因干擾,就正是多個指數增長的複合干擾,不停地產生多面向的幾何成長以及幾何衰退,而回歸到個體後,更會有所謂的函數特性與時期不同的函數變化(如:情緒的高檔期、疲勞的低檔期等等)會需要不同的設計,這也是為什麼學員的訓練上每人都不盡相同,因此所需要的判讀方式與設計更是有特異性。
學員常常判讀錯誤,敏感與硬度正相關,但是在單獨判讀的時候會因為訓練時期的不同產生混雜。比如,成長期就屬於非線性不可單一判讀,而硬度穩定後就可以單一的判讀表達,相同的器官卻有著完全不同的行為模式與計算方法,更別說還要加上情緒反應與疲勞問題等等。另外,單一刺激源硬度,單一刺激源敏感,進入線性刺激可判讀,但是混和型的低敏感高硬度,高敏感低硬度,就會產生非線性資料,切割後又是完全不同的獨立表現,甚至是產生新的指標來源。
所以我們原先的神經網路單層線性模型,無法解決線性不可分問題,因此也讓我們的機器動態判讀的計畫產生較大的問題。
八、模型的建置
在2016年後我們參考用了反向傳播演算法來設計我們的陰莖敏感的神經網路。這邊簡易教學一下類神經網路的基本原理,先讓資料訊號通過網路,輸出結果後、計算其與真實情況的誤差;再將誤差訊號反向傳播回去、對每一個神經元都往正確的方向調整一下權重;如此來回個數千萬遍後,機器就學會如何辨識一種陰莖的敏感反應。在多次的資料倒流後,就可以針對多種的陰莖敏感反應做判斷。
反向傳播時,正常的資料處理會設定更正錯誤的方法──「代價函數」(Cost Function)。代價函數是預測陰莖敏感結果和陰莖敏感的真實結果之間的差距。代價函數的優化 (Optimization) 是機器學習的重要研究目標,也就是:如何找到優化的最佳解(機器判讀誤差的最小值)?如何用更快的方式逼近最佳解?
如何逼近最佳解有很多種不同的演算法,最典型的方法是採用隨機梯度下降法 (Stochastic Gradient Descent)。當線性關係資料的代價函數為凸函數,找到最佳解不是問題;然而問題在於非線性關係的資料:其代價函數為非凸函數,求解時容易陷入局部最佳解、而非全域最佳解,這個問題叫做梯度消失問題 (Vanishing Gradient)。
但糟糕的是,梯度消失問題會隨著神經網路層數的增加而更加嚴重,意即,隨著梯度逐層不斷消散、導致神經網路對其神經元權重調整的功用越來越小,所以只能轉而處理淺層結構(比如 2 層)的網路,從而限制了性能。(比如射精閥值神經元、情緒神經元、硬度神經元)
也因此我們的陰莖反應判別原本以為可以有效的突破神經網路學習的阻礙,多層次的學習存在著太深的技術阻礙,所以面對這樣的狀況,也只能透過人為篩選,將所有的陰莖敏感設定型態與定義,把深度學習的目的,切割成許多小區塊的淺層機器學習。
畢竟超過多層的神經網路學習,會造成多變因的錯誤,跟不可能的組合(比如陰莖敏感反應高昂興奮,但相關變數為重度疲勞,陰莖軟化,然後持久力提升。但是因為陰莖軟化跟持久力提升已經有很大的落差了,即便機器學習上是可行,但在人類真實行為上真的出現機率過低,所以我們機械學習的投資上線量化產生了阻礙)。
所以我們只能針對目前的狀態,以針對淺層的機械學習資料做設計(比如:分割為陰莖敏感與藥物影響、分割為陰莖敏感與營養影響、分割為陰莖敏感與高血壓、分割為陰莖敏感與營養影響、分割為陰莖敏感與持久力、分割為陰莖敏感與情緒刺激、分割為陰莖敏感與疾病影響、分割為陰莖敏感與情緒影響、分割為陰莖敏感與情緒影響、陰莖敏感與肥胖等等數以百計的小單元)。
再透過風險模型的設計,針對各項影響要素,根據個人的狀態,導入所需求的小單元,比如肥胖、手淫錯誤、情緒刺激等等建立小型的風險模型,再進一步的進行訓練方針上的改變去修正風險模型。等到訓練完成後,也就可以透過風險模型去預測是否會產生衰退,以及如何去預防。 但是問題點在於即便是建立風險模型,也要減少模型間干擾要素,比如疾病與情緒這兩個單元,容易有正相關,而這兩個正相關相依性過高就會產生所謂的數據偏差值提升,導致本來主角的陰莖敏感,被雙變因的數據相近給拉走,導致數據上會失準,所以我們就從小型的風險模型建立。未來我們就能夠在陰莖衰退以及產生影響與退化時,精準的找出原因,及時解決。算是對於我們多年投資上找到了新的出路。
這些年來我們也發現了有國外學者,成功解決了反向傳播的優化問題,我們也檢視過這樣的方法或許可行,我們的南爵訓練的陰莖數據資料早已分類好超過7萬筆,平均一個學員一年就能產生,600筆固定數據,可變形混合數據,更是可以達1800筆,雖然我們在深度學習的部分已經暫停了投資,改走向男性生理風險控管與陰莖強化結合,但是我們希望有朝一日可以有更高的技術單位可以一起與我們合作完成南爵數據在這門研究上的遺憾之珠。
九、後記:
深度神經網路可以自動學習特徵,而不必像以前那樣還要請專家以人工建造特徵,大大推進了智能自動化 (就好比陰莖受損了也在後續的特徵反應形成差異,那麼在設定權值與係數上的問題就可以自動解決) 。
而因為我們走的是以標註的資料,所以學習上希望的是依循產生的結果與對應方法,所以應用像是淺層學習的方法反而更適合我們。
雖然我們的進展最後只到淺層的學習,但是對於我們來說透過數據的學習知識上,也回歸到一個重點,就是是否掌握關鍵資料以進行分析。所以我們回頭針對最原始的資料開始進行分析、分類、趨向判定、以及解讀,並且朝向健康風險控管方向執行,也相信未來一定可以完成線上AI的判讀以協助訓練。
希望我們提出的數據與多年見解可以讓生物數據學習上更精進,也希望我們解釋錯誤上有問題可以給我們批評指教。如果有各單位在生物數據分析與學習上需要技術的合作都可以透過官方EMAIL與我司聯繫。
技術與參考
2006 年可以說是深度學習起飛的一年。經過了三十年的研究,Hinton在《Science》等期刊發文,指出「具備多層隱藏層的神經網路具有更為優異的特徵學習能力,且其在訓練上的複雜度可以通過逐層初始化來有效緩解」。
這篇驚世駭俗之作名為《Reducing the dimensionality of data with neural networks》。在這篇論文中, Hinton 提出深度信念網路、使用無監督預訓練方法優化網路權值的初始值,再進行權值微調 (Fine-Tune),讓多層神經網路能夠真正被實踐。
又由於神經網路的研究在過去被棄置已久,故 Hinton 教授又將深度神經網路重新換上「深度學習」(Deep Learning) 的名字捲土重來,Hinton也因此被稱為「深度學習之父」。
話說回來,目前已經沒什麼人在使用 RBM 或深度信念網路了;後來的研究發現,簡單的初始化和激發函數的調整,才是解決 Vanishing Gradient Problem 最好的方法。現今最為廣泛被使用的方法是「多層感知器 (MLP) + ReLU函數」。




0 意見:
張貼留言